[GN] Part 1: Sending to localhost
How much network traffic can we produce with Rust? Isn’t this a weird thing to ask? It probably is, but with knowing this and moreover, how to achieve it, we can create a network application from the bottom up, that is ensured not to be bottlenecked by the network send throughput. Furthermore, we can more easily benchmark the more interesting aspects like receive-performance, when we know that the sender is not the limiting factor. Throughout this article, I will present several approaches to gradually increase throughput until my CPU finally was completely busy and the system became unresponsive. In some sorts, this article is the first part of a continuation to the Tokio article
The plan
As in my last post, I will start by maximizing the amount of packets per second the application can send, then the bandwidth can easily be increased by increasing the packet size.
Let’s start with some pseudocode (nearly executable python), to describe what needs to be done:
buffer=[...]
counter=0
timestamp()
while counter < 100_000_000:
send()
counter+=1
print(timediff())
In this first step, we simply don’t care if our packets reach their destination, so we can as well send them to somewhere they will be ignored like 127.0.0.1:42 (assuming nothing is listening on port 42). Note that this way we are not limited by the capabilities of our network card in this first step but expect to see results that we will most likely not achieve on real hardware.
The straight-forward approach: std::socket
Let’s start with the straight-forward approach: just use, what the std lib provides us. In this firt iteration’ this simply is a single thread, executing the rust-equivalent to the above pseudocode. This means we execute such a function, sending a lot of zeroes:
pub fn send_packets_to(&self, amount: u32, size: u32, to: SocketAddr) {
let buf = vec![0 as u8; size as usize];
for i in 0..amount {
self.socket.send_to(&buf, &to).expect("Send failed");
}
}
Note that we send the same buffer over-and-over again and do not re-allocate memory for it (at least not in our code).
So, how well does this work? Let’s mangle the results with a bit of R and see what we got:

Packet rate versus size when sending with the std::socket functions
Let me highlight some observations:
- The packet rate does not change considerably if we send messages of 2 bytes or 265 bytes.
- Up until
2^11bytes we have quite stable performance of about 450K packets per second. Note however that this already equals450000 * 2^11 * 8 = 7 Gbit/swhich is probably more than you are prepared to pay for in a cloud-environment for prolonged times. - We are sending to localhost here. This means in particular, that we do not involve any network cards or even such mundane things as ethernet MTUs that will limit us if we try to do this in a real scenario later on.
I conclude that it is not worth anything network-performance-wise to optimize package sizes below 256 bytes. In terms of traffic costs, this migtht be another story. We will later see how packet size influences parsing or cryprographic operations.
Now we can have a look at the average bandwidth and see if this is matches what the OS tells us while the benchmark is running.

Sent Bandwidth versus size when sending with the std::socket functions
As you can see, we reach impressive bandwidths, that are completely unrealistic if we write to an actual network device. So what is the next logical step? Of course:try to generate even more unrealisitc numbers: Currently we use only one thread but most of our machines have more than one core. So let the premature optimization begin. (You will later see why this might be not that stupid)
More threads with std::socket
The code in this section does not make that much sense in a server implementation: We will create multiple sockets that send to somewhere. So why write it? With such code we can later test our receive rates, since we will (most likely) accept packages from several clients at the same time.

Sent Bandwidth versus size when sending with the std::socket functions
As before, the packet rate does not decrease horribly until a packet size of 2^12 bytes.
Wait a second, are you telling me, that we satureate about 150 Gbits/s of bandwidth? Have a look yourself:
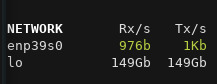
According to glances, we generate about 150 Gbit/s of traffic
Going deeper: SO_REUSEPORT
In this section we will utilize multiple cores to send from one socket. If we used the std::socket implementation to bind on the same address from multiple threads it would crash and tell us that the address is already in use. Mhm. Luckily we can get around this: We can set some socket options to allow exactly that. But at what cost? The only thing we have to sacrifice is that we cannot run our code on windows servers anymore, but that is a sacrifice I am willing to make.
According to the docs, we need to set the flag SO_REUSEPORT.
Unfortunately the rust std lib does not allow us to do this and we therefore need to use a crate that extends the capabilites of our socket creation: socket2.
With socket2 we can set the SO_REUSEPORT flag with the accoring methods:
let socket = Socket::new(
Domain::ipv4(),
Type::dgram(),
Some(Protocol::udp())
).unwrap();
socket.set_reuse_port(true);
socket.set_nonblocking(true);
socket.bind(&addr.into());
let socket = socket.into_udp_socket();
Now we can bind multiple times to the same socket, e.g have 12 threads send from “127.0.0.1:9000”. Note however, that if we try to send faster than the system is able to handle, there might be no guarantees whether the kernel will drop packets and if so, from which thread they are.

Packets per second versus thread count
The last thing to ask here is, can we gain a few more packets per sacket by optimizing the rust code itself? Perhaps even modify internals of a library? Luckily, we don’t need to. The amount of time spent in our code is so small, we cannot even see it in the Flamegraph below.

According to the flame graph, we cannot gain much in terms of rust code. (Click on it, the graph is interactive)
You can see that the code calls “__libc_sendto” internally and we therefore do not need to optimize any loops or such things in our rust code. However, there are still options we need to keep in mind for later: real-hardware might produce an entirely different picture but we will see when we come to that.
Next steps
Until now, we only sent traffic on out local host, what is quite boring. To get more realistic numbers, we need to send our traffic through real hardware. In a future article I will try to do exactly this, but my laptop has only a one gigabit port. Luckily you can rent hardware on a per-hour basis for affordable prices. As soon as the receiving side is ready, I will test send and receive speeds on real hardware.